What is Bayesian statistics? (oversimplified)
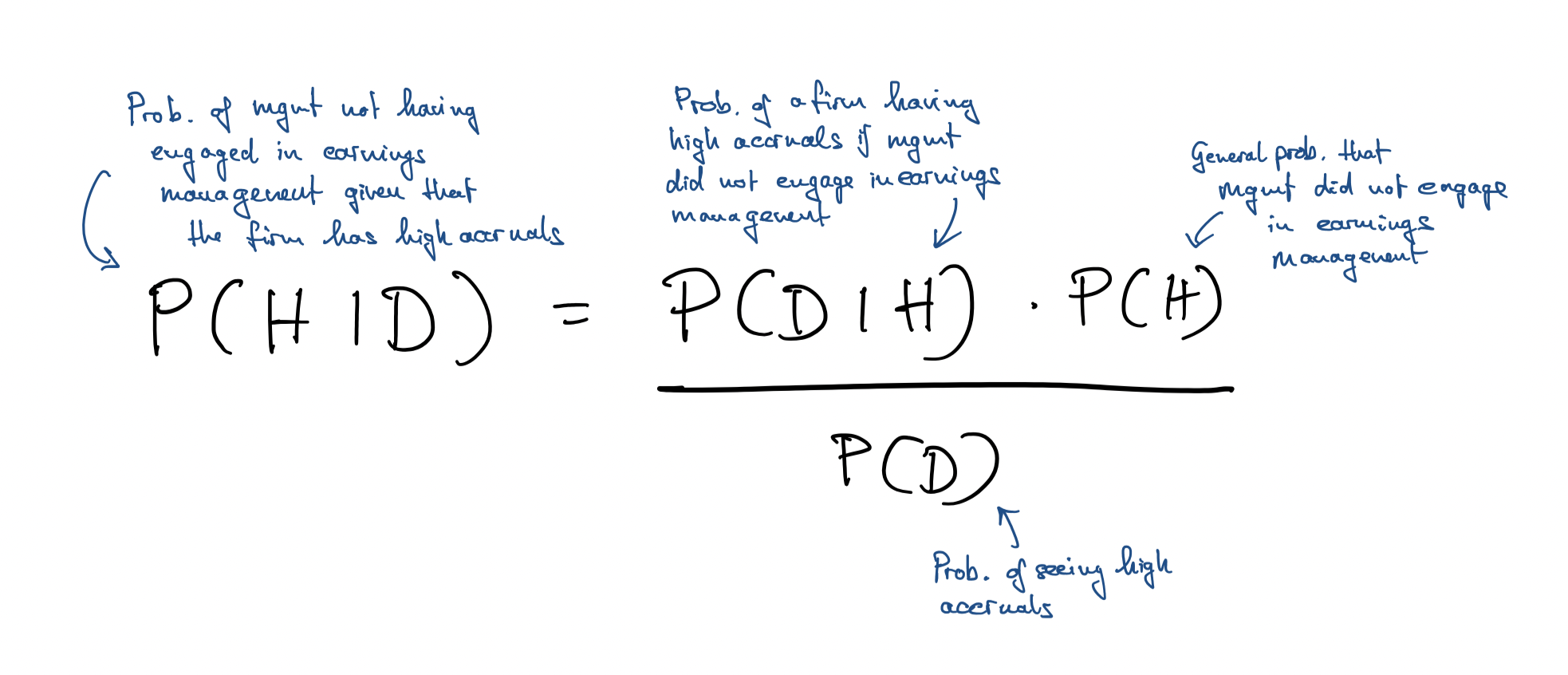
Frequentist: \(P(Data|Hypothesis)\)
Bayesian: \(P(Hypothesis|Data)\)
Why learn a bit of Bayesian statistics?
Photo by Erik Mclean

Not because of the philosophical differences!
To better understand frequentist statistics
To add another tool to our workbench:
- Sometimes the data is not informative enough
- Priors and DGP helps encode additional information/assumptions
- Useful for constructing finer measures and measuring latent constructs
Example: Precise firm-level measures
\[R_{i,t} = a_i + b_i * X_{i,t} + u_{i,t}\]

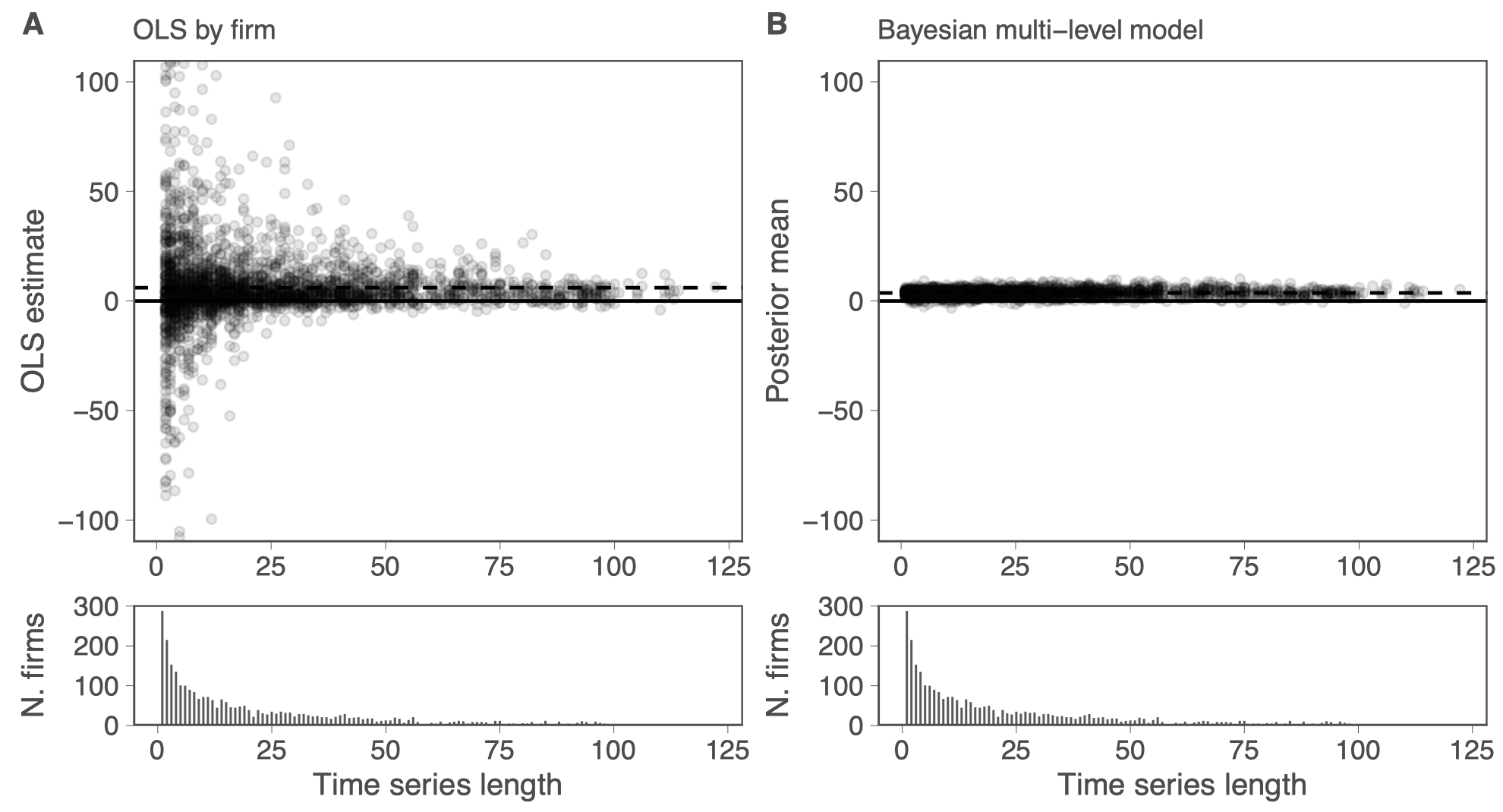
Cross-learning the prior. Helps discipline noisy estimates
Example: Modeling uncertainty

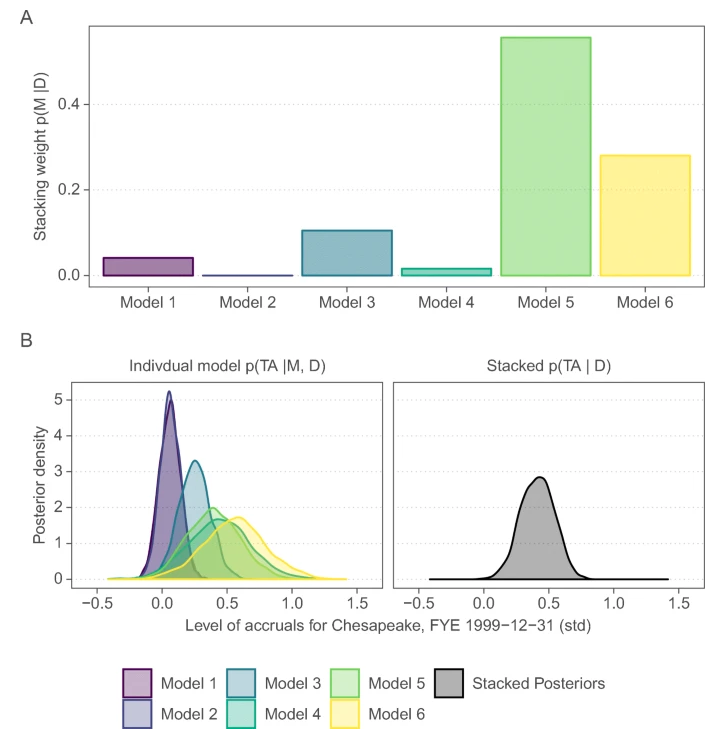
When we do not trust our models we should average. Increases power and reduce false positives in tests for opportunistic earnings management


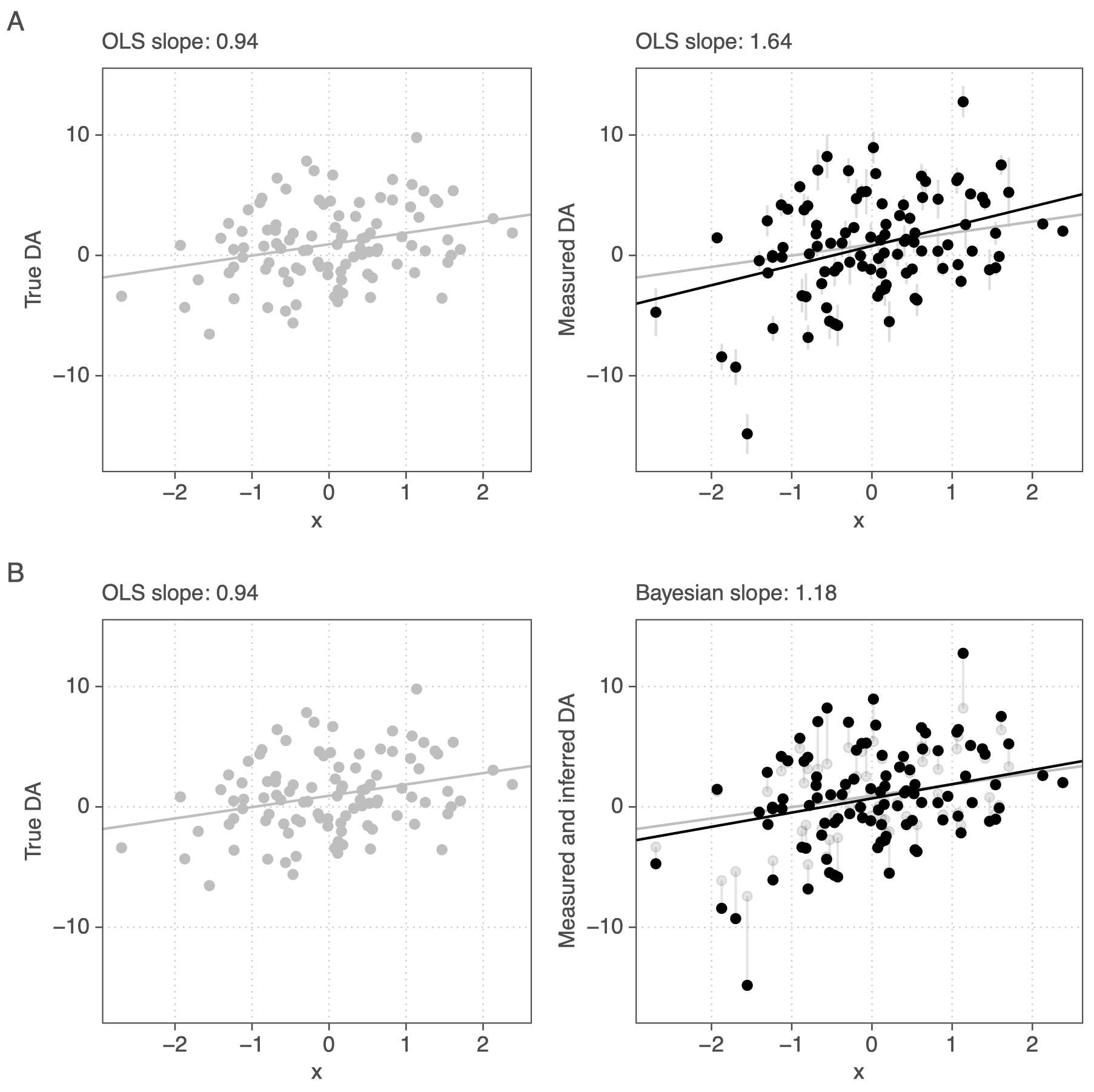
Unmeasured influences cause estimates to vary
\[y = 1 + 2 \times x + u ,\ u \sim N(0, 20),\ x\sim N(0,1)\]
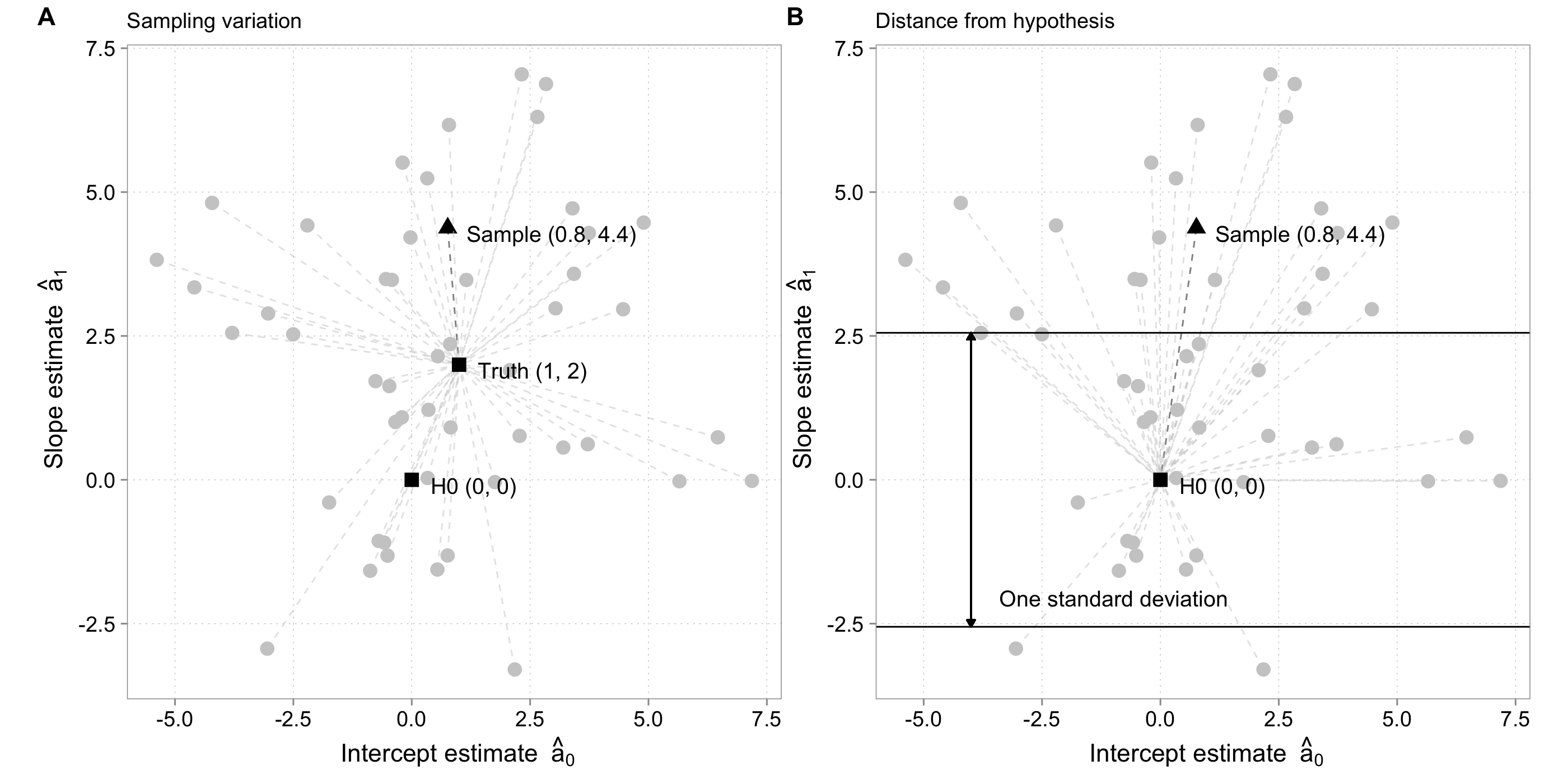
Hypothesis tests judge the data’s distance from \(H_0\)
Test logic:
- Compute a “normalized distance” from \(H_0\) using S.E.
- Figure out what distribution describes distance (assumptions)
- Pick a threshold. When is an estimate considered too distant?
- Too distant means: Unlikely to be generated under \(H_0\)
Normalization: S.E. depends on assumed behavior of unmeasured determinants (\(u\)) and \(N\)

Be careful interpreting coefficient magnitudes in low power situations
- Coefficients very large for those intervals that do not include zero
- Gets worse with less power (unexplained variance vs. N obs)
- “That which does not destroy my statistical significance makes it stronger” fallacy
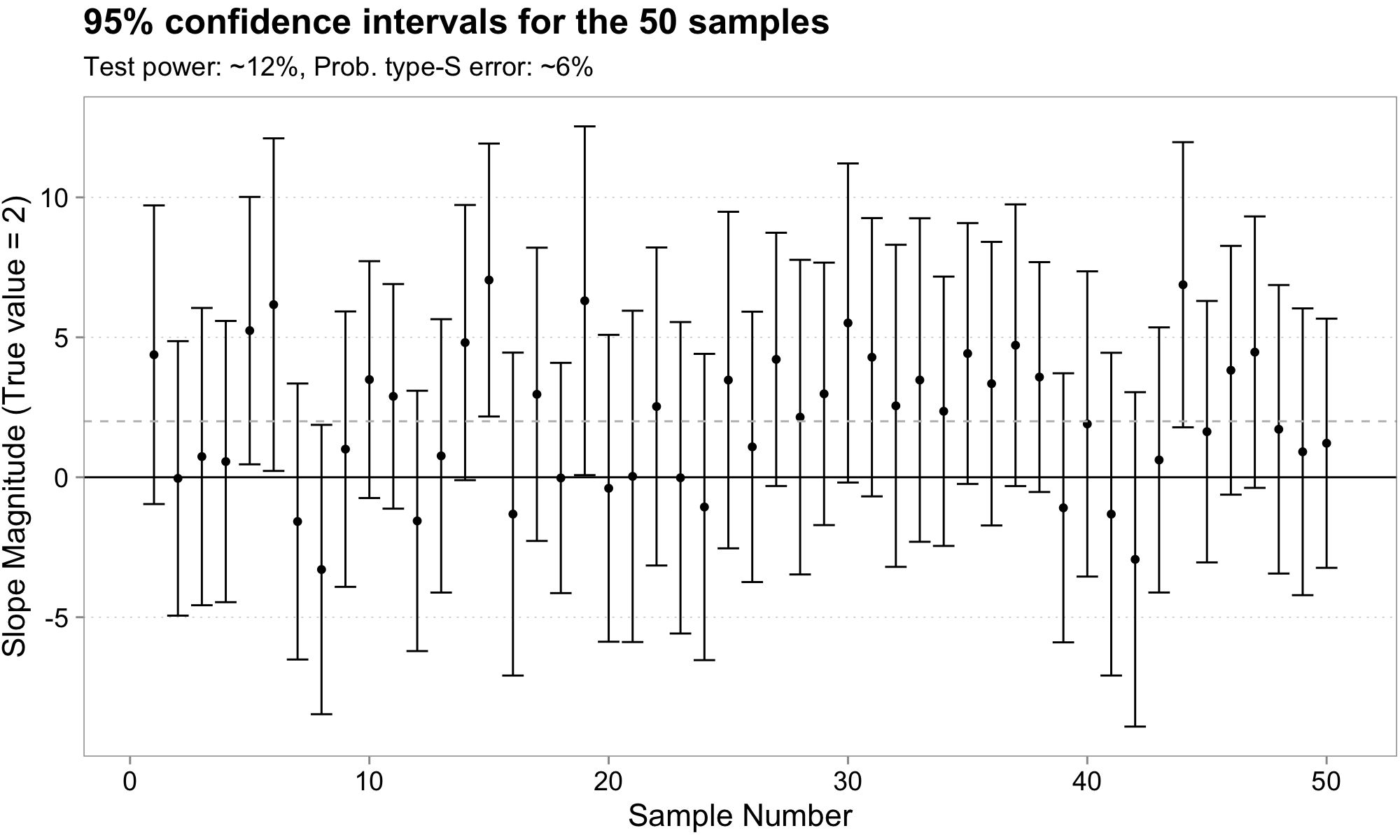
But my N is > 200.000 obs. Power is not an issue
Well … Let’s remember this picture
Effective N goes down quickly once we want to estimate heterogeneity in something we care about
And then there is overfitting…
Drawing 5 samples from \(y \sim N(-200 + 10 * x, (x+30)^2\)

Overfitting means we fitted sample idiosyncrasies
| Sample | In-Sample MSE Difference | Avg. Out-of-Sample MSE Difference |
|---|---|---|
| 1 | -8.5 | -15.1 |
| 2 | -1419.8 | 1770.0 |
| 3 | -778.7 | 901.7 |
| 4 | -2735.2 | 4602.0 |
| 5 | -8.4 | -15.1 |
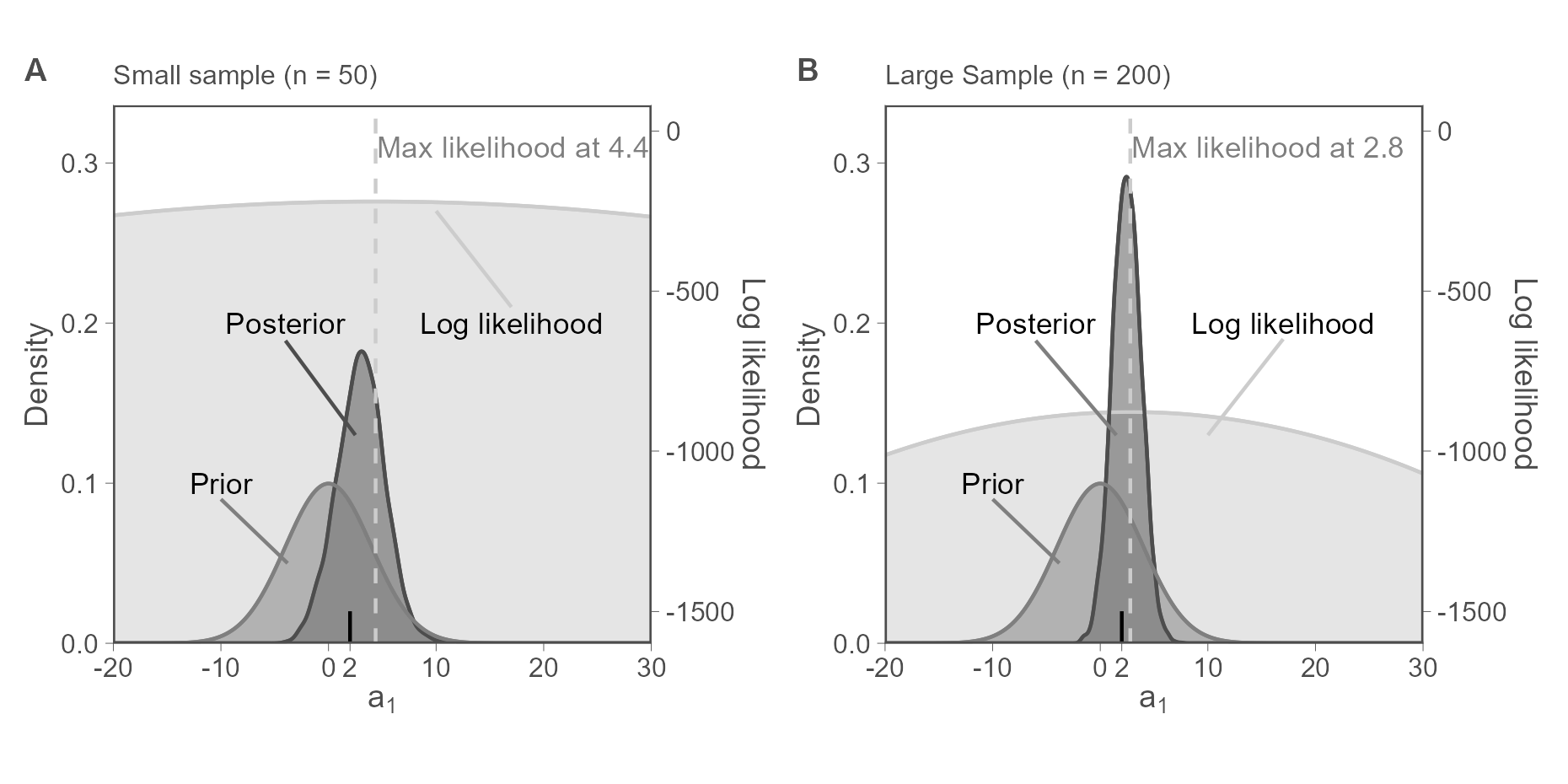
No additional information in the DGP
We basically get the same inference as with classic OLS

A weakly informative prior disciplines the model
Our posterior beliefs about \(a_1\) have moved closer to the truth.

Priors have little weight when data is informative
An implication of the weighted average formula
Priors help variable selection (think Lasso)
Especially relevant when:
- Variables are noisy proxies
- Variables are correlated (including interactions)
If we can assume that only a few covariates are effectively non-zero, we want sparse priors
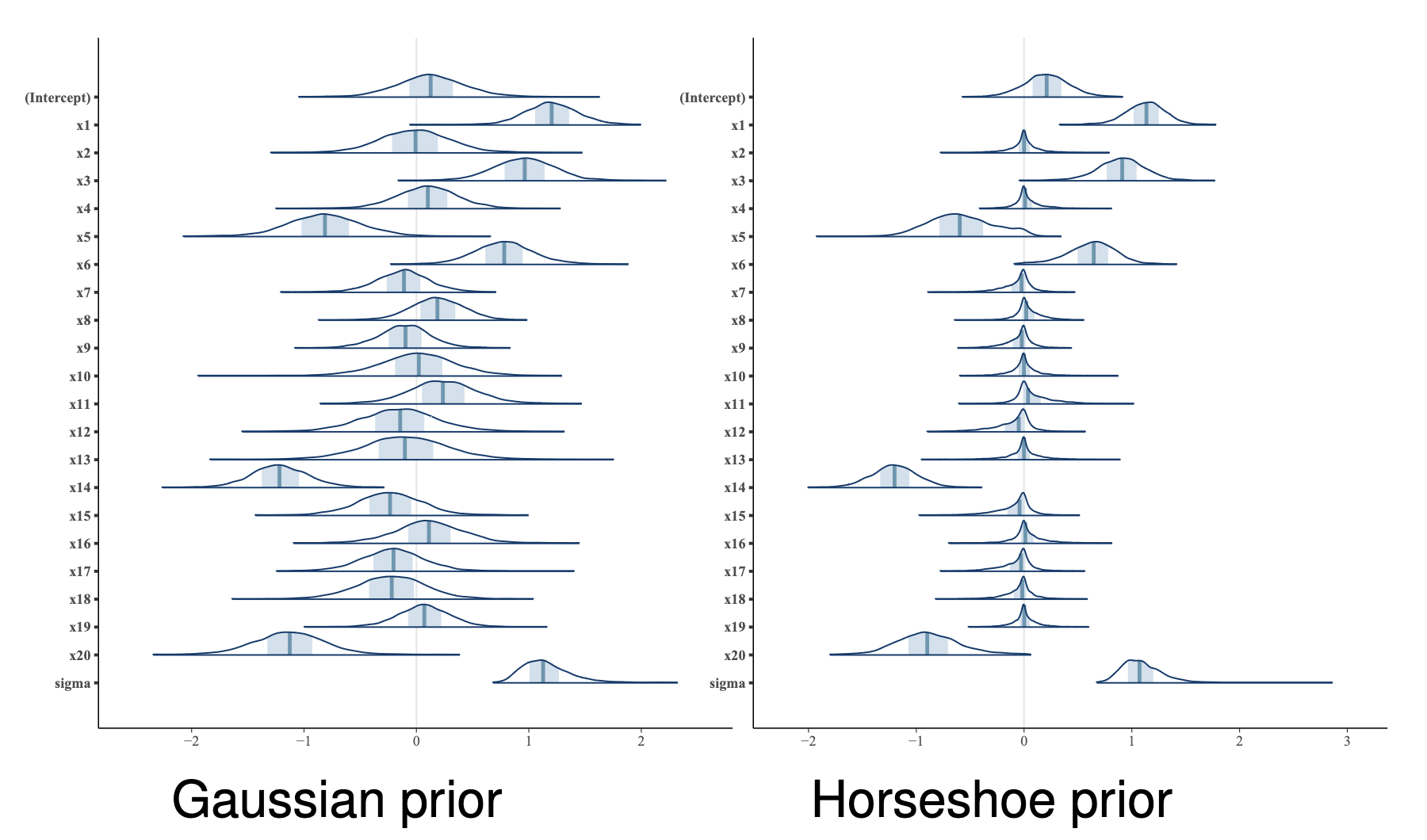
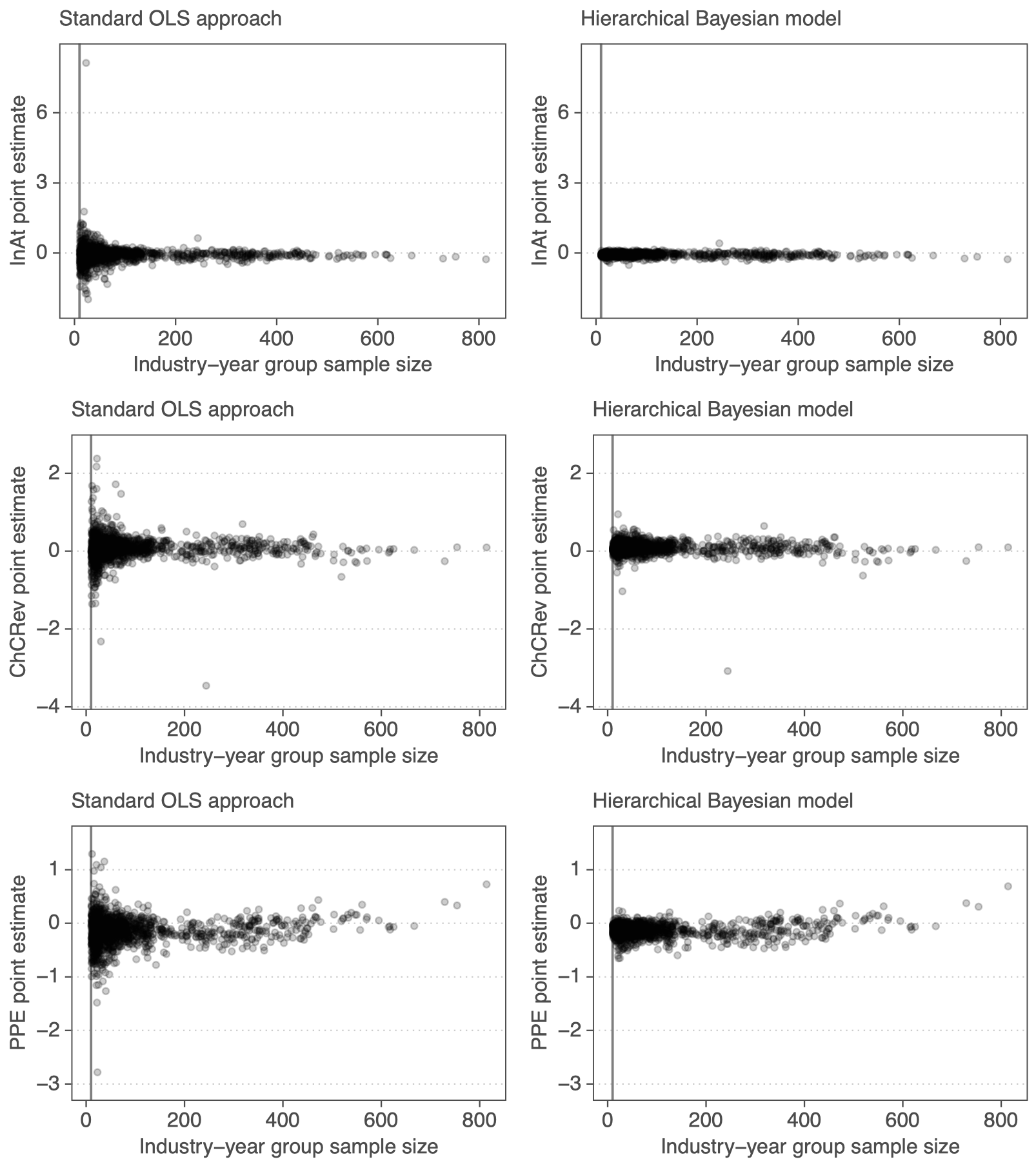
Priors can be learned from the data
We can estimate priors, assuming that units come from the same distribution
\[ \begin{align} TA_{ijt} & = \beta_{0,jt}InvAt_{ijt-1} + \beta_{1,jt}\triangle CRev_{ijt}\\\nonumber & + \beta_{2,jt}PPE_{ijt} \end{align} \]
Priors:
\[ \begin{eqnarray} \label{eq:priors} \begin{pmatrix} \beta_{0,j,t}\\ \beta_{1,j,t}\\ \beta_{2,j,t} \end{pmatrix} & \sim & N\left(\left(\begin{array}{c} \mu_0\\ \mu_1 \\ \mu_2 \end{array}\right),\left(\begin{array}{ccc} \sigma_{0} & \rho_{0,1} & \rho_{0,2} \\ \rho_{0,1} & \sigma_1 & \rho_{1,2} \\ \rho_{0,2} & \rho_{1,2} & \sigma_2 \end{array}\right)\right) \quad \forall j,t \end{eqnarray} \] Hyper-priors:
\[ \begin{align} \mu_d & \sim N\left(0, 2.5\right) \quad \sigma_d \sim Exp\left(1\right) \quad \forall d \nonumber \\ \rho & \sim LKJcorr(2) \end{align} \]
We want regularized measures + their uncertainty
Measurement error has serious consequences for our inferences