Warning: package 'collapse' was built under R version 4.5.2
source("hhs-ggtheme.R")
8.1 Your task: predicting renovation costs
You are working for a hotel chain, Eden resorts. Eden resorts owns 598 hotels in various big cities and tourist destinations all across Europe. You are working on the financial planing for the upcoming year. Right now, you are tasked with predicting the group-level costs for renovating rooms. When looking at the financials of recent years, there seems to be quite a bit of variation across hotels and locations, so you decide to take a closer look at what predicts renovation costs. Not only will it help you with your current planing, but this might be useful information for future expansion plans.
8.2 Theory as the starting point
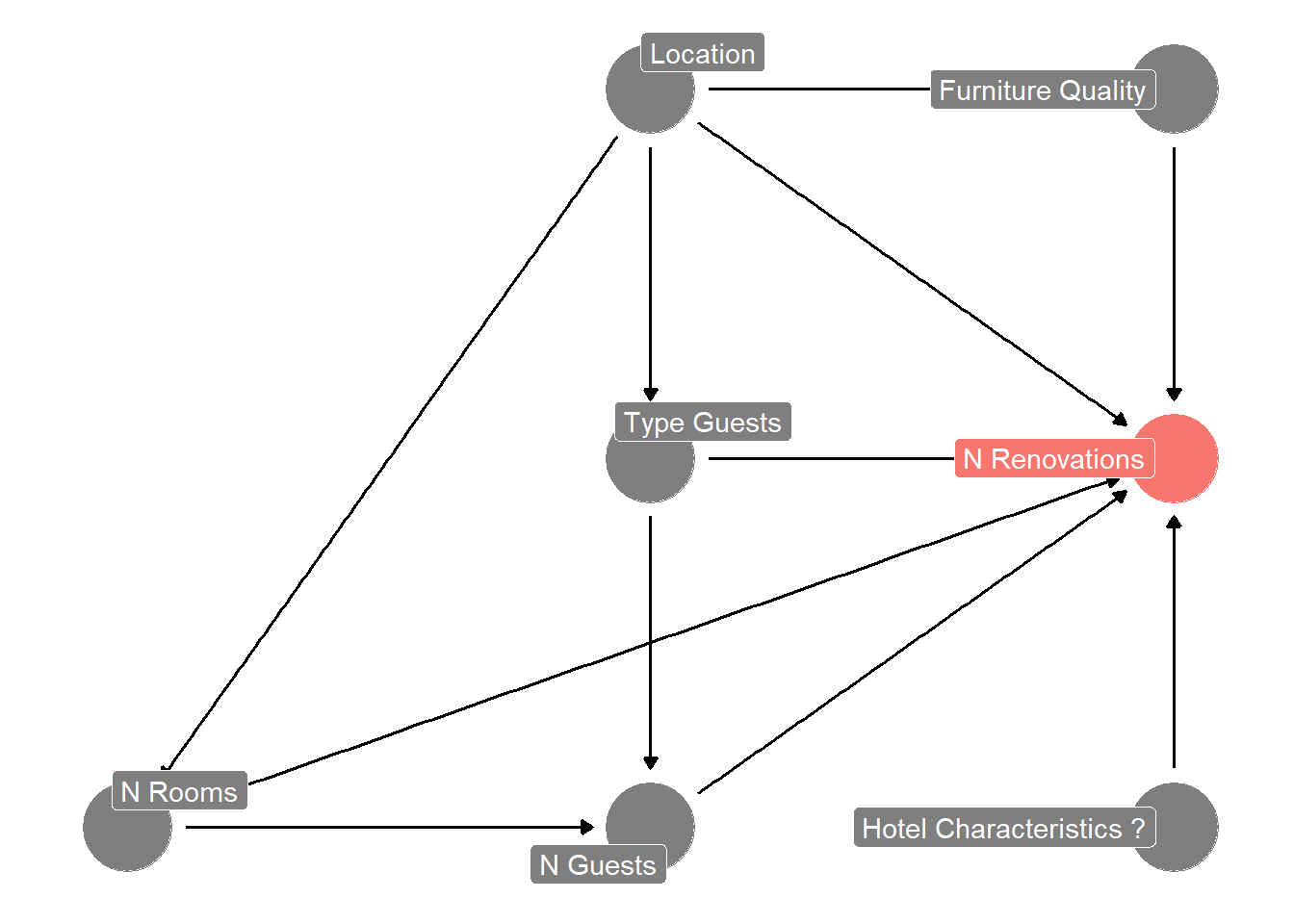
You know that you can collect some data from the hotel chain’s systems, so you first start sketching out a mental model of what might be important predictors. You start with something like this Figure 8.1:
Figure 8.1: DAG of possible determinants of the N of hotelroom renovations
8.3 The data
It is quite usual to adjust your mental model as you go and learn from what the data tells you. The sketch above is just a rough starting point and you should adjust it, once you start thinking more about the problem. But it is good enough to get started. For now, you use Figure 8.1 to guide your data collection efforts. You extract the following data from Eden’s systems:
8.4 Exploratory analysis to get familiar with the data
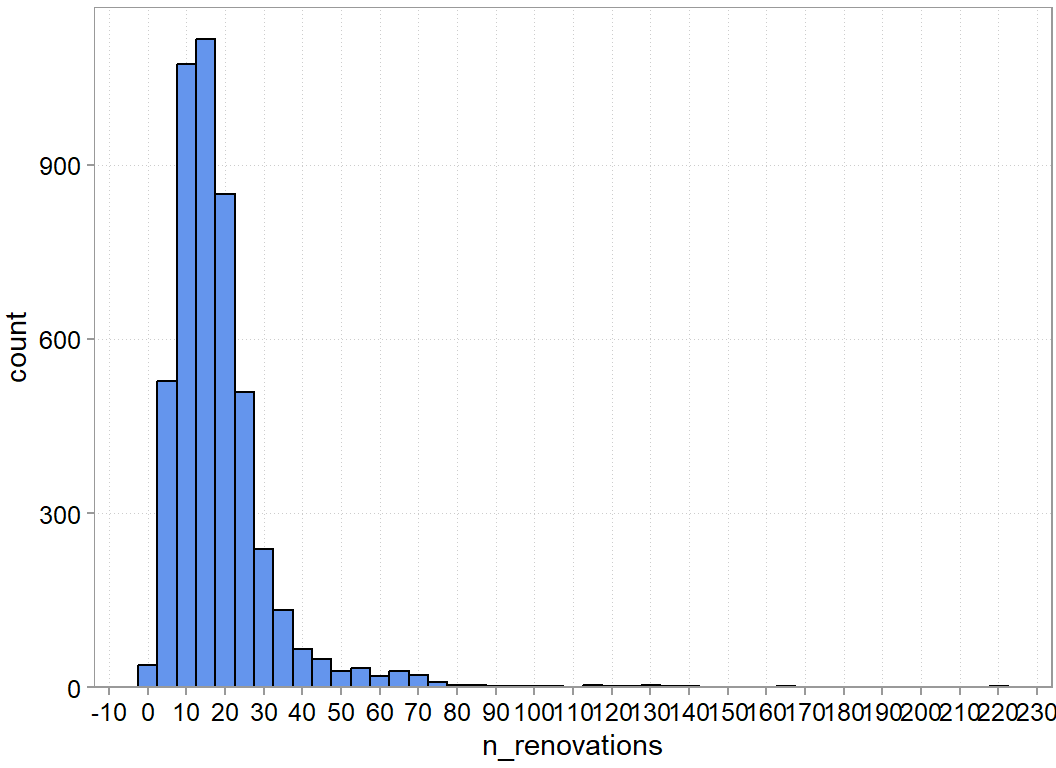
A good first step is to examine the outcome variable of interest. A histogram to examine to univariate distribution and some descriptive statistics are usually enough to give you a sense of the data:
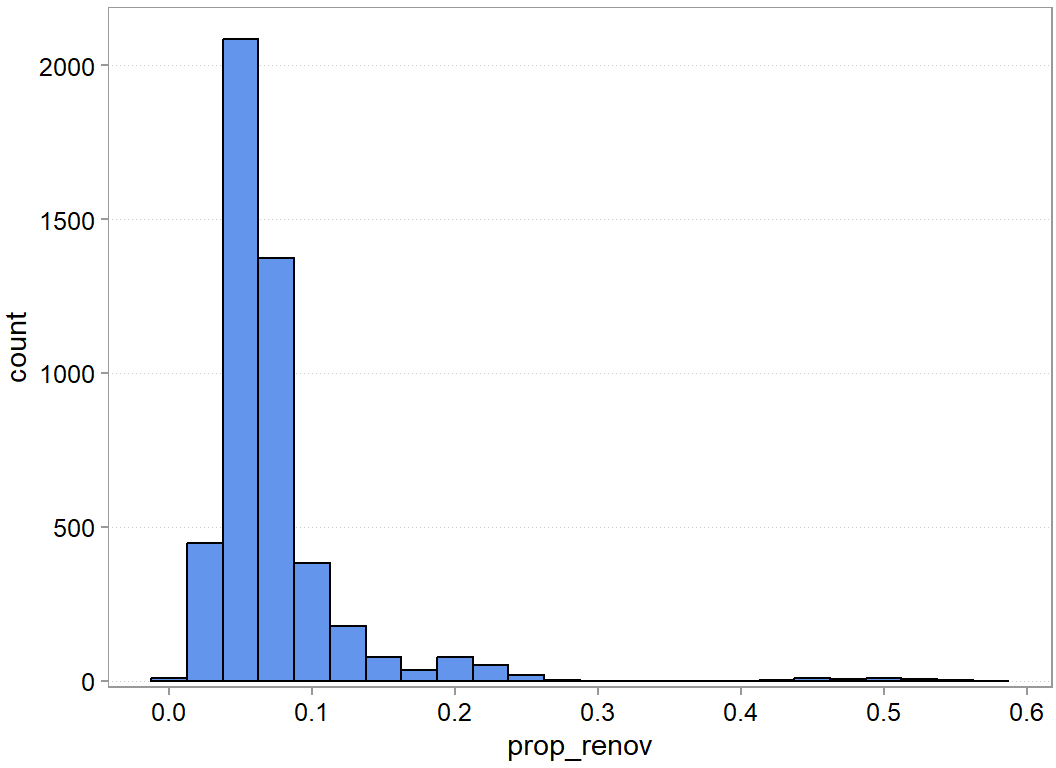
Figure 8.2: Empirical distribution of the outcome variable
# here we use the collapse::descr functiondescr(dta$n_renovations)
Dataset: n_renovations, 1 Variables, N = 4784
--------------------------------------------------------------------------------
n_renovations (numeric):
Statistics
N Ndist Mean SD Min Max Skew Kurt
4784 114 18.88 15.57 1 220 4.73 41.36
Quantiles
1% 5% 10% 25% 50% 75% 90% 95% 99%
3 5 7 10 16 22 31 42 76
--------------------------------------------------------------------------------
8.5 Preparing the data for our comparison of different prediction models
When we compare many different models, we will always run the risk of choosing an overfit model when selecting a model based on estimates of out-of-sample performance. Even, though we will use cross-validation (discussed in Chapter 5), we can never really get rid of the fact that we are re-using and re-using the training data and will eventually be fooled by noise. So, we want to keep a bit of the data out of the training routine, so that we can asses the out-of-sample performance of the model we eventually select a bit better. We do this via the initial split function. Here we actually use a group_ split function. The reason is that we have a panel. We have hotel data for multiple years. We want to make sure that we randomly select hotels and *not’ hotel-years. By defining hotel_id as a grouping variable we make sure that all years of a hotel are in the same split (either in training or in testing).
We could also stratify slightly by the outcome variable. What this does is it sorts n_renovations in 3-4 buckets (think: low, medium, high) and ensures that training and test are roughly comparable in their proportions of low, medium, and high number of renovations. This is just a precaution to make sure our testing set is not randomly tilted in terms of the outcome. In our case, we cannot do that however, because we do not have enough data to do such stratification. So we will have to live without
set.seed(47) splits <-group_initial_split(dta, prop =0.8, group = hotel_id)dta_test <-testing(splits)dta_train <-training(splits)splits
<Training/Testing/Total>
<3824/960/4784>
Next, we prepare our cross-validation folds. Again, because we have a smallish sample, we use five folds. If we had more, we’d probably go up to ten folds
set.seed(48)folds <-group_vfold_cv(dta_train, v =5, group = hotel_id)print(folds)
Because number of renovations is a positive integer number, classic and poisson regressions are natural starting point for a predictive analysis. We define both model classes for use later.
Next, we define our different models. These are a combination of 1) outcome variable, 2) predictors (think x-variables) to use and 3) pre-processing (transformation) steps to be applied to the outcome or predictor variables. Such pre-processing steps could be turning a factor variable into dummy variables, adding squared terms of a particular x variable as an additional predictor, changing the scale of some predictor, and so on.
Below we just tried a few combinations to illustrate how to set up different models. We start with a recipe that defines what the outcome variables are (the variables to the left of ~) and what the predictor variables are (the variables to the right of ~). Then we apply different (pre-processing) steps.
lin_model <-linear_reg(mode ="regression", engine ="lm")pois_model <-poisson_reg(mode ="regression", engine ="glm")# basic steps we want in all models:r0 <-recipe(dta_train) |>step_normalize(all_numeric_predictors()) |>update_role(n_renovations, new_role ="outcome")# Individual versions of inputs for each model# Each one updates the preceding version. r1 <- r0 |>update_role(c(n_rooms, n_guests), new_role ="predictor")r2 <- r1 |>update_role(c(family_guests, young_tourists, business_traveller),new_role ="predictor" )r3 <- r2 |>update_role(price_rank, new_role ="predictor") |>remove_role(c(family_guests, business_traveller), old_role ="predictor") r4 <- r3 |>remove_role(c(young_tourists), old_role ="predictor") |>step_dummy(price_rank)r5 <- r4 |>step_poly(n_guests)
Once we have defined all our models, we combine them into what tidymodels calls a workflowset. With the cross = TRUE option, we will have every combination of model specification and model class as one model in our workflow set.
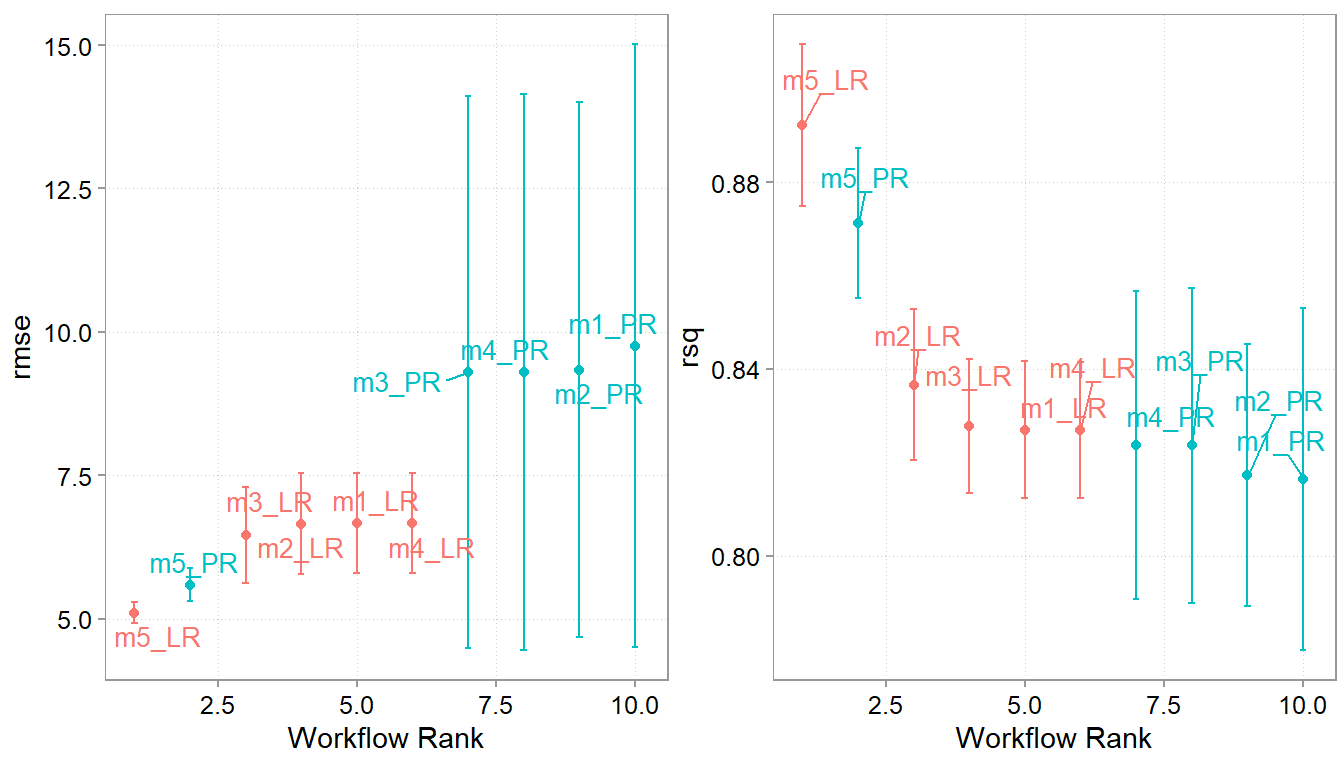
We now take the defined workflowset and test each model in it on the cross validation folds. Afterwards we use the rank_results function to rank the different models according to the root mean squared error metric. We chose RMSE because we are concerned about large errors. We use the verbose option in case there are model hiccups. If there is something going awry (e.g., a rank deficit matrix because we accidentally selected fully co-linear variables) then the verbose option will tell us which work flow had an issue.
model_set1_fits <- model_set1 |>workflow_map("fit_resamples", # Options to `workflow_map()`: seed =1101, verbose =TRUE,# Options to `fit_resamples()`: resamples = folds, control =control_resamples(save_pred =TRUE) )
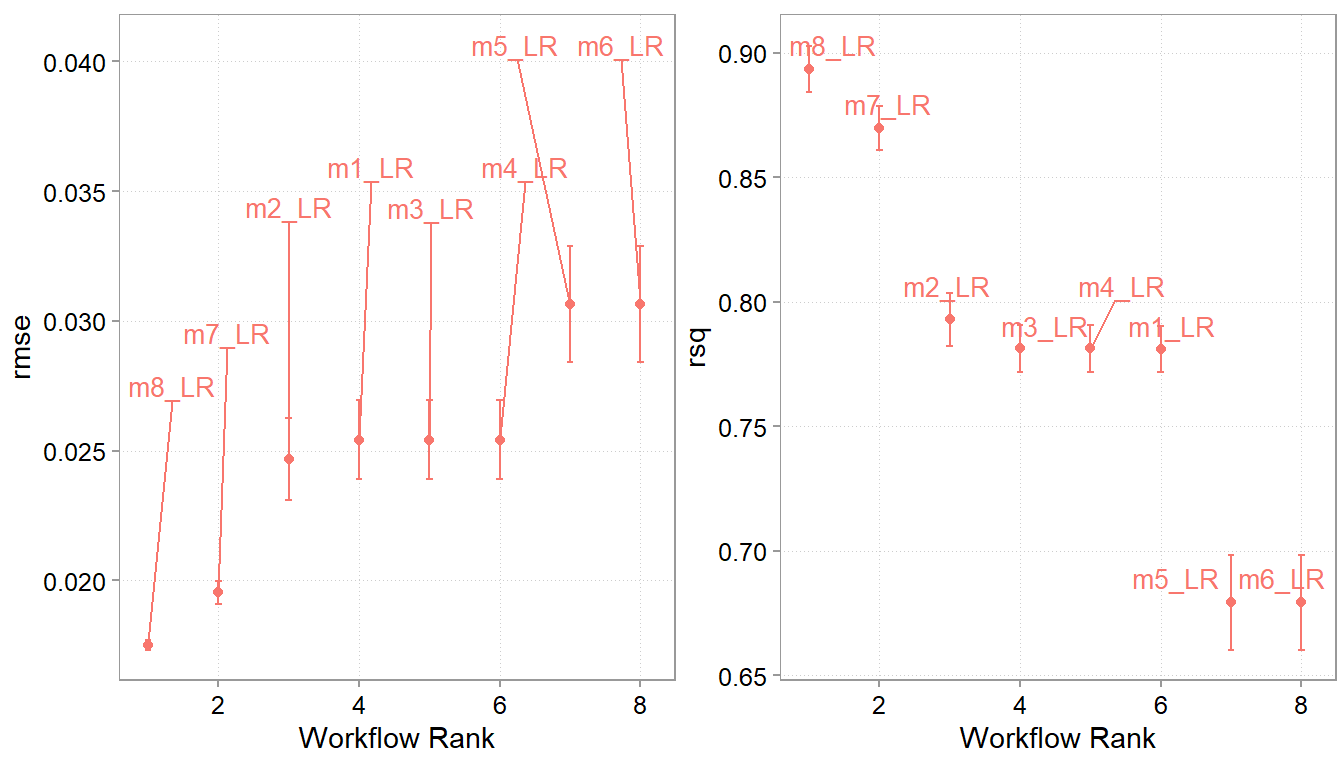
Figure 8.3: Prediction performance of different models in terms of RMSE and R-squared
Apparently, the last model with a polynomial specification and price rank dummies does best. Let us take this as our chosen model. We now take it and fit it to the whole training data. And then we will finally assess how well it does on the test sample.
8.6.1 Fitting the chosen model
We choose the best combination via its workflow id wflow_id, fit it to the whole training data this time, and use it to predict the time to repair on the 20% test sample we have not used yet. To better explore the performance of our model it often helps to add our predictions to the test sample:
best_wf_id <- results_ranked$wflow_id[1]chosen_wf <-extract_workflow(model_set1_fits, best_wf_id)# we want to refit the best model/workflow on the full training setchosen_wf_fit <-fit(chosen_wf, data = dta_train)# Now we can use the fitted model to predict on the test setchosen_wf_pred <-predict(chosen_wf_fit, new_data = dta_test) |>bind_cols(dta_test)head(chosen_wf_pred)
.pred
hotel_id
year
location_id
business_traveller
young_tourists
family_guests
other
n_rooms
n_guests
price_rank
n_renovations
21.30290
2
1
51
0.5015014
0.0980488
0.3003494
0.1001005
275
14339
1
17
20.72327
6
1
1
0.5983723
0.1010449
0.3005828
0.0000000
345
12592
3
18
20.36197
7
1
20
0.3017600
0.3002343
0.3980058
0.0000000
436
10609
3
19
10.34511
25
1
15
0.4000042
0.1022022
0.4977937
0.0000000
194
5901
2
10
11.84515
30
1
57
0.5996767
0.2008716
0.1994516
0.0000000
162
8447
2
17
13.04520
34
1
30
0.1993054
0.0987191
0.6016988
0.1002767
294
6707
2
14
Finally, we can see what the RMSE is on the held-out test data
rmse(chosen_wf_pred, truth = n_renovations, estimate = .pred)
.metric
.estimator
.estimate
rmse
standard
5.391455
mae(chosen_wf_pred, truth = n_renovations, estimate = .pred)
.metric
.estimator
.estimate
mae
standard
3.693395
So on average, we are off by 3.6 renovations by year or 5.3 root squared renovations. Given that the mean number of rennovations in the full dataset is 18.9 and the median is 16 that MAE is ca 23% of the median. So, in terms of magnitude it is still sizable. How expensive this error is, we can only assess once we know the cost of a renovation though.
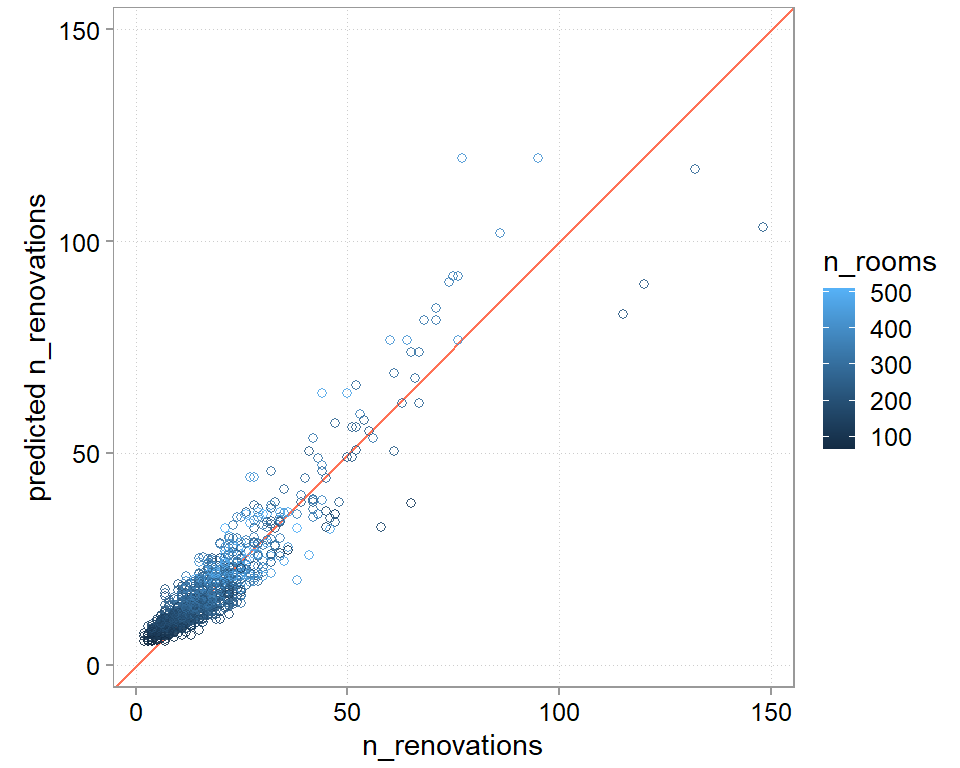
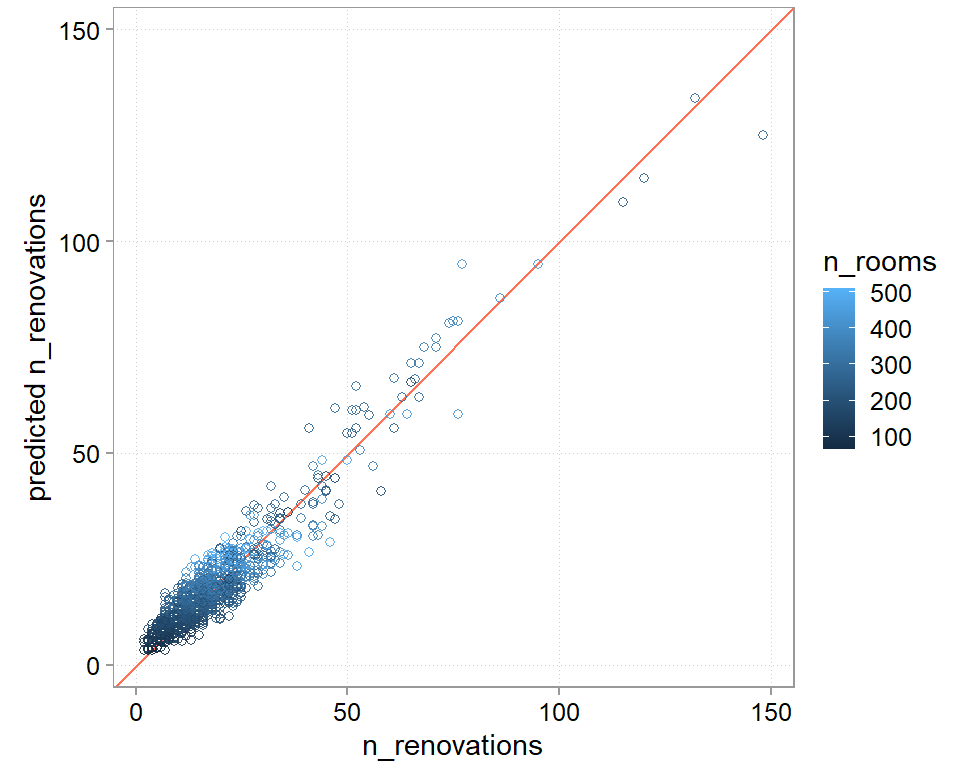
We should also always look at a plot of predicted versus actual outcomes. This looks quite decent. We do seem to struggle a bit with the outliers. Also, while a bit hard to see, we seem to not do so well at the very low end ever. We seem to systematically overshoot the hotel-years with a very low number of renovations.
chosen_wf_pred |>ggplot(aes(y = .pred, x = n_renovations, color = n_rooms)) +scale_y_continuous(limits =range(chosen_wf_pred$n_renovations)) +scale_x_continuous(limits =range(chosen_wf_pred$n_renovations)) +geom_abline(intercept =0, slope =1, color ="coral1") +geom_point(alpha =0.9, shape =21) +labs(y ="predicted n_renovations") +theme(legend.position ="right")+coord_fixed(ratio =1)
Figure 8.4: Predicted values versus actual outcomes
8.7 An alternative set of model with transformed outcomes
Sometimes we can improve predictive performance by transforming the outcome variable. This can sometimes make the functional form tying the outcome variable to predictors more easy to fit. In our case, the number of renovations is obviously heavily dependent on the number of rooms the hotel has. Maybe a better question to ask is: what proportion of hotel rooms is renovated? We can then also frame the number of guests as a proportion of rooms to get to a predictor that reflects how often the average room is used (something like room booking frequency). These transformed variables might be be closer to the underlying mechanism that determines how fast a room “wears out”. Let us do these transformations and try everything again:
Figure 8.5: Empirical distribution of the outcome variable
descr(dta2$prop_renov)
Dataset: prop_renov, 1 Variables, N = 4784
--------------------------------------------------------------------------------
prop_renov (numeric):
Statistics
N Ndist Mean SD Min Max Skew Kurt
4784 2367 0.07 0.05 0.01 0.57 4.63 33.4
Quantiles
1% 5% 10% 25% 50% 75% 90% 95% 99%
0.02 0.03 0.04 0.05 0.06 0.08 0.11 0.15 0.25
--------------------------------------------------------------------------------
This is still a pretty skewed distribution. The descriptives show you that we have one year where more than 50% of the rooms were renovated. So, visually it is hard to tell whether this outcome might or might not be hard to get right. Let us carry on nevertheless. It seems a bit easier to reason about it.
We do our data preparation steps again. This time we do a split that is aware of hotel_id and we also do a cross-validation that is aware of hotel_id. This means, that we effectively randomly choose hotels for the test and training set and for the different folds. This is important because we want to make sure that we do not accidentally train on the same hotel in the training and test set.
set.seed(47)splits2 <-group_initial_split(dta2, prop =0.8, group = hotel_id)dta_test2 <-testing(splits2)dta_train2 <-training(splits2)set.seed(48)folds2 <-group_vfold_cv(dta_train2, v =5, group = hotel_id)print(folds2)
Because we have transformed the outcome variable, the RMSE is now in terms of renovation proportions and not renovations anymore. So, when we want to compare our new predictions with the old ones we need to create a new variable that is the predicted proportion of renovations times the number of rooms (line 15 below)
Just out of curiosity, do we have any observations, where we predict a negative proportion? (Which would be obviously non-sensical?)
chosen_wf_pred2 |>filter(.pred <0)
.pred
hotel_id
year
location_id
business_traveller
young_tourists
family_guests
other
n_rooms
n_guests
price_rank
n_renovations
prop_renov
room_freq
pred_renov
It does not look like it. That is a good sign for our model fit. For the range of predictors we have in the test sample, we do not get obvious non-sense
rmse(chosen_wf_pred2, truth = n_renovations, estimate = pred_renov)
.metric
.estimator
.estimate
rmse
standard
4.35196
mae(chosen_wf_pred2, truth = n_renovations, estimate = pred_renov)
Figure 8.6: Prediction performance of different models in terms of RMSE and R-squared
Our transformation did seem to help. We managed to get the RMSE down quite a bit and also slightly reduced the MAE. We can double check the coefficients of our regression model as well to see whether the coefficients are looking reasonable. However, there is an important caveat here. The coefficients might not be intuitively interpretable. That is because we have not designed the regression with isolating specific associations in mind. We only cared about prediction performance when designing the model. You need a DAG again, to see whether and how you can interpret the coefficients.
Figure 8.7: Predicted values versus actual outcomes
It looks like the transformed regression really helped us doing a better job at the outlying observations (That is also why the RMSE went down more than the MAE). We also seem to do a better job with the hotel-years with low number of observations. This is a common reason why we want to think about transformations in the first place. Whenever we see that we have trouble predicting a specific part of the distribution correctly, we might want to see whether we can transform the distribution to something easier to fit.
8.8 Takeaway
Similar to our example in Chapter 5, we still need to decide whether we can use the last model for our cost forecasts problem. The individual error still seems large. It is 22% of the median of number of renovations. So, how should we proceed. We could carry on and try to improve the model. Rethink our mental model based on what we learned and maybe, if possible, collect additional predictors that we have not yet considered. Before doing that though, we should first remember that our goal is to forecast group-level renovation costs. So we a) also need costs pre renovation (which likely varies by location and hotel) and b) need to look at the error in agreggate renovations. Because that is ultimately what we want to forecast. If individual errors cancel out, we might do okay with the model we have already. So let us have a look at aggregate errors
chosen_wf_pred2 |>summarize(agg_n_renov =sum(n_renovations),agg_pred_n_renov =sum(pred_renov),.by = year )
year
agg_n_renov
agg_pred_n_renov
1
2179
2186.087
2
2426
2460.168
3
2205
2201.324
4
2255
2242.882
5
2225
2256.381
6
2088
2148.629
7
2075
2105.781
8
2473
2498.596
That looks quite okay for all the years we have date in our test sample. We need cost per renovation to make the ultimate decision, but this model might be good enough to carry on with your budget planing.